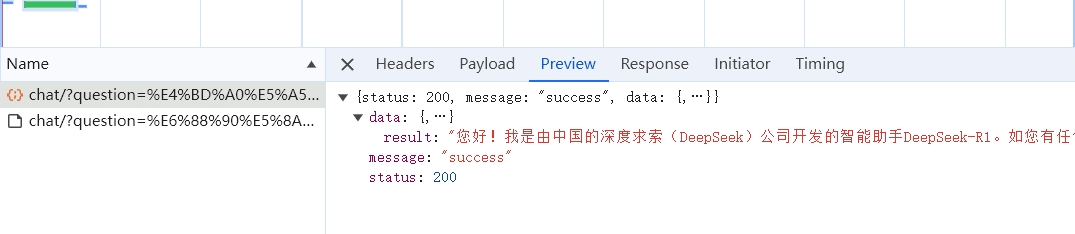
本地大模型部署--仿DeepSeek
目标DeepSeek-1.5B本地部署
- 部署方式:
将大型预训练模型(如GPT、Llama、BERT等)完全部署在用户自有的硬件设备(如服务器、本地计算机)上,而非依赖云端API服务
特点:
私有化:模型和数据完全存储在本地,无需通过互联网传输
自主控制:用户拥有模型的完整权限,可自由修改、训练或调整推理逻辑
离线运行:无需网络连接即可使用模型能力(如生成文本、分析数据)
- 模型下载
讲解大模型网站,一个国外的(huggingface但是我浏览器打不开网站,代码中直接使用地址下载的),一个镜像网站https://hf-mirror.com/
huggingface.co 这个网站上各种类型的大模型都有,所有训练大模型都从这里开始,在现有的基础上进行训练
安装huggingface的下载工具(python库):pip install huggingface-hub
下载模型文件:
1 | set HF_ENDPOINT=https://hf-mirror.com # 加速下载设置 |
(后续在view.py中国添加下载模型文件的代码,运行时自动下载的)
前端
客户端–uniapp
看官方文档目标:看文档–写代码–实现https://uniapp.dcloud.net.cn/
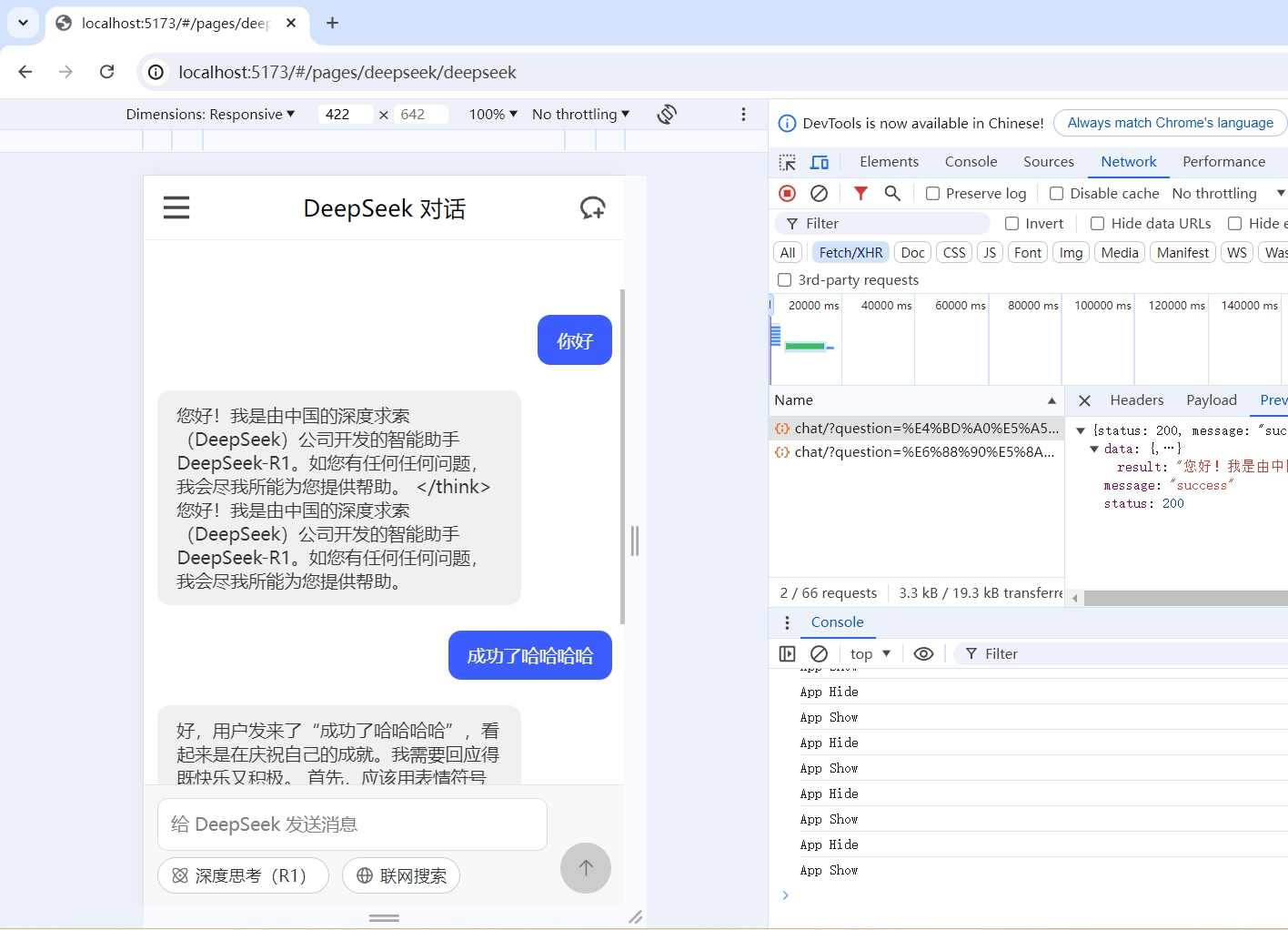
直接把deepseek页面截图发送给deepseek让它生成页面代码,自己小改一下input和发送按钮
测试:
前端发送数据,F12/Payload能看到前端发送出来的请求
后端
认识Django框架,创建文件
服务器端–Django 框架
https://www.djangoproject.com/pip install django===4.2pip install django-cors-headersconda list djangoS D:\Pragram code\bigModel\modelBg\xhserver> python manage.pypip install transformers
xhserver/主要两个文件:
seetings.py 全局配置
urls.py 一级路由创建应用
服务器要创建一个应用(根据官方文档建文件cv官方文档代码)python manage.py startapp aichat100(添加100表示这是自定义的)
这个新建的chat100文件夹主要做两件事情:一个写视图,一个写路由
videws.py 视图
urls.py二级路由(对应views下的chat)
views.py
1 | # from django.shortcuts import render |
新建urls.py(二级路由)
1 | from django.urls import path, include |
在一级路由中添加
xhserver.py添加一行path('ai/', include('aichat100.urls'))
1 | from django.contrib import admin |
- 启动后端服务
启动:python manage.py runserver
url能看到,成功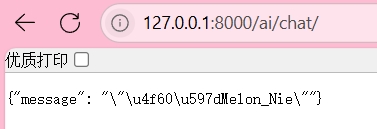
但是现在中文乱码SON 中文默认转义输出的问题,Django 默认会将非 ASCII 字符(如中文)转义成 Unicode 编码,是 Django 的默认行为
方法一:设置 ensure_ascii=False
修改你的视图代码,在构造 JsonResponse 时加上 json_dumps_params={‘ensure_ascii’: False}1
2
3
4
5
6
7from django.http import JsonResponse
def chat(request):
data = {
'message': '你好Melon_Nie'
}
return JsonResponse(data, json_dumps_params={'ensure_ascii': False})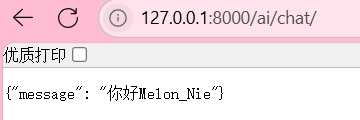
集成大模型–参数讲解
重点是view.py文件,参数讲解
- device
概念:指定模型运行的计算设备(CPU 或 GPU)。在 PyTorch 中通常为 “cpu” 或
“cuda:0”。
设置建议:优先使用 GPU(如 device=”cuda:0”),显存不足时用 CPU。 - torch_dtype
概念:模型张量的数据类型,如 float32(高精度)、float16 或 bfloat16(低精度,节省显
存)。
影响:精度越高(如 float32),结果越精确,但显存占用更大。精度越低(如 float16),
显存占用少,但可能损失精度或数值不稳定。
设置建议:GPU 推荐 torch.float16 或 bfloat16(兼容性需确认);CPU 通常用 float32。 - max_length
概念:生成文本的最大长度(token 数量)。
影响:值越大,生成内容越长,但速度越慢,且可能重复或偏离主题。值过小可能导致回答不
完整。
设置建议:根据任务调整:对话建议 100-300,长文本生成可设 512-1024,注意模型最大限
制(如 4096)。 - do_sample
概念:是否启用采样策略(如 top_k, top_p)。若为 False,则使用贪心解码(确定性强)。
影响:True:输出多样化,适合创意任务。False:输出确定性强,适合事实性问题。
设置建议:需要多样性时设为 True,需准确性时设为 False。 - top_k
概念:采样时保留概率最高的前 k 个 token。
影响:值越大(如 100),候选 token 多,输出多样但可能不相关。值越小(如 10),输出
更确定但可能重复。
设置建议:通常设为 10-50。 - temperature
概念:控制采样随机性,调整概率分布平滑度。
影响:值大(如 1.5):输出随机性高,可能不连贯。值小(如 0.1):输出更确定,但易重
复。
设置建议:平衡点常为 0.7-1.0;需创造性时调高(如 0.9),需保守时调低(如 0.3)。 - top_p(核采样)
概念:从累积概率超过阈值 p 的最小 token 集合中采样。
影响:值大(如 0.95):候选 token 多,输出多样。值小(如 0.5):候选 token 少,输出
更集中。
设置建议:常用 0.7-0.95。 - repetition_penalty
概念:惩罚重复 token 的权重(>1.0 时抑制重复,<1.0 时鼓励重复)。
影响:值大(如 2.0):减少重复,但可能生成不自然内容。值小(如 1.0):无惩罚,默认
行为。
设置建议:通常设为 1.0-1.2,明显重复时可设 1.2-1.5。
集成大模型–安装+实现
这部分几乎完全按照老师给的文档(大模型文档提炼版)抄,遇到问题问AI,安装各种包,
runserver一半卡出,需要进行:python manage.py migrate应用数据库迁移pip install torch torchvision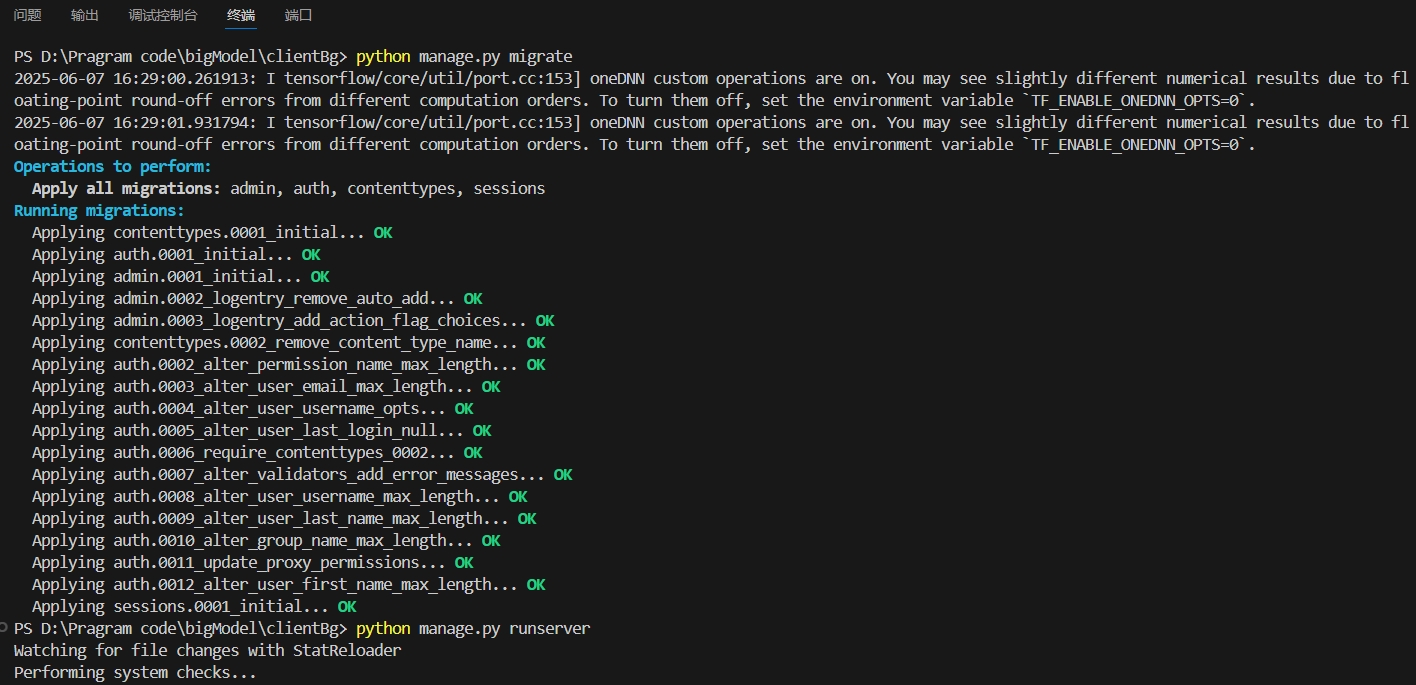
最后 python manage.py runserver 运行项目进行大模型下载
下载时在view.py文件头两行添加如下代码,切换国内镜像(但是我还是下了一个小时)
1 | import os |
我的后端可以了,但是一直返回中文卡住了很久,其实这里不用管的,前端后面会解决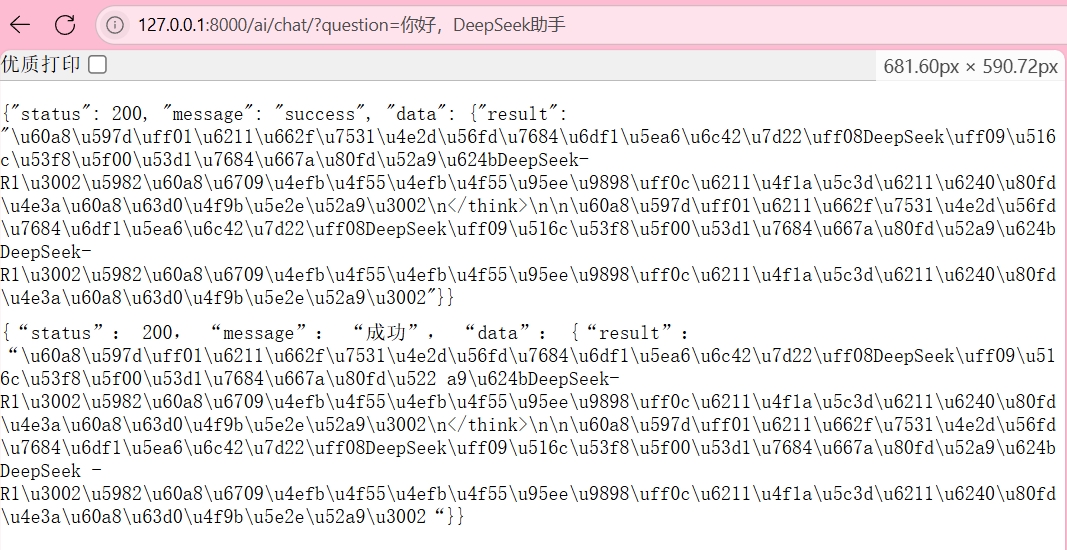
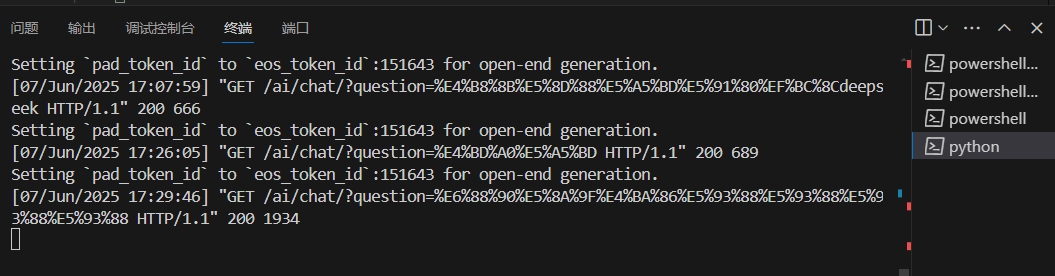
但是我的前后端没有打通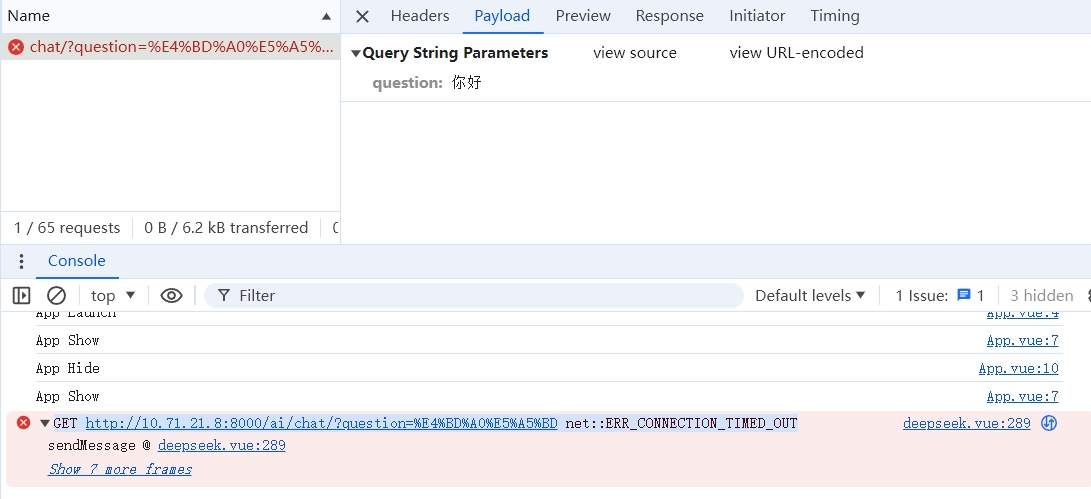
倒腾倒腾倒腾,成功
成功!