浏览器--学习笔记
写在前面:
本文内容大部分来自deepseek、通义和Kimi助手的回答
强烈推荐!!这个视频特别棒!!:
B站卢克儿的视频:【干货】浏览器是如何运作的
AI推荐的相关网站:
Can I Use:查询特性支持度
MDN Compatibility Tables
Modernizr:特性检测库
关于浏览器常见兼容性问题的文章:
csdn田兴的文章–前端常见浏览器兼容性问题解决方案
浏览器是如何工作的
浏览器解析流程:
输入与解析 URL
浏览器解析 URL:确定协议(如 HTTP/HTTPS)、域名、端口、路径、文件名、查询参数等组成部分。检查缓存
缓存查询:浏览器检查本地缓存,看是否有该资源的副本。
使用缓存:如果缓存命中且资源未过期,直接使用缓存内容,跳过后续步骤。DNS查找:
DNS将域名转化为IP
(比如输入的是 www.example.com,但计算机通信只能用 IP 地址(如 93.184.216.34),需要一个“翻译器”——DNS)
查询过程:检查浏览器缓存。查询本地 hosts 文件。向本地 DNS 服务器发起请求。若本地 DNS 服务器无结果,逐级向根域名服务器、顶级域名服务器和权威域名服务器查询。完整查询流程
浏览器缓存:先看浏览器里有没有最近解析过的结果。
操作系统缓存:如果浏览器没有,就查操作系统的 DNS 缓存。
hosts 文件:本地配置文件,可能手动指定了某些域名对应的 IP。
本地 DNS 服务器:通常是你网络服务商提供的。
逐级查询:如果本地 DNS 没有结果,它会去问更高层的服务器:
根域名服务器 → 顶级域名服务器(如 .com) → 权威域名服务器(负责具体域名)。建立连接:
通过TCP三次握手与服务器建立连接,如果是HTTPS还需要进行SSL/TLS握手以确保安全传输。
三次握手:
浏览器发送 SYN 包到服务器,请求建立连接。
服务器回复 SYN-ACK 包,确认连接请求。
浏览器发送 ACK 包,完成连接建立发送HTTP请求:
构建请求:浏览器构造 HTTP 请求,包含请求方法(如 GET)、请求头(User-Agent、Cookie 等)和请求体。
发送请求:通过已建立的 TCP 连接,将 HTTP 请求发送到服务器。服务器处理请求:
服务器处理请求后返回HTTP响应,包括状态码和实际的网页内容(通常是HTML文档)。
解析HTML:
接收请求:服务器接收并解析 HTTP 请求。
处理请求:
静态资源:直接返回请求的文件(如 HTML、CSS、JavaScript、图片等)。
动态资源:执行相应的程序(如 PHP、Python、Node.js),生成响应内容(如 HTML)。
构建响应:服务器生成 HTTP 响应,包含状态码(如 200 OK)、响应头和响应体。接收并处理响应
接收响应:浏览器接收服务器的 HTTP 响应。
解析响应:
解析 HTML:构建 DOM 树,表示页面的结构。
解析 CSS:构建 CSSOM 树,确定样式规则。
构建渲染树:结合 DOM 树和 CSSOM 树,生成渲染树,包含需要显示的元素及其样式。加载资源:
在构建DOM的同时,如果遇到外部资源链接(如CSS、JavaScript文件或图片等),浏览器会异步发起新的HTTP请求去下载这些资源。解析CSS:
对于CSS,浏览器会创建CSSOM树,这是一个包含了所有样式规则的对象模型。
解决冲突:通过优先级(!important > 内联 > ID > Class > 标签)确定最终样式执行JavaScript:
当浏览器遇到<script>标签时,它会暂停HTML解析,转而执行JavaScript代码。这是因为JavaScript可能会影响DOM或CSSOM。构建渲染树:
把DOM树和CSSOM树合并,浏览器构建渲染树,这是一个只包含需要显示元素(隐藏元素如 display: none 会被排除)的信息的树形结构,得到一个得到带样式和结构的渲染树布局:
计算每个元素在屏幕上的确切位置和大小,这一过程称为“布局”或者“重排”。绘制上色(Paint):
根据布局的结果,浏览器将元素绘制到屏幕上(把布局信息转换成屏幕上的像素),这一过程称为“绘制”。合成显示(Composite):
将所有图层按正确顺序合成最终图像(如果页面有多个图层,浏览器会将它们合并成一个图像),然后呈现给用户
优化技巧:使用 transform 和 opacity 动画可跳过布局和绘制,直接合成
浏览器是如何渲染UI的:
浏览器获取HTML文件,然后对文件进行解析,形成DOM Tree
与此同时,进行CSS解析,生成Style Rules
接着将DOM Tree与Style Rules合成为 Render Tree
接着进入布局(Layout)阶段,也就是为每个节点分配一个应出现在屏幕上的确切坐标
随后调用GPU进行绘制(Paint),遍历Render Tree的节点,并将元素呈现出来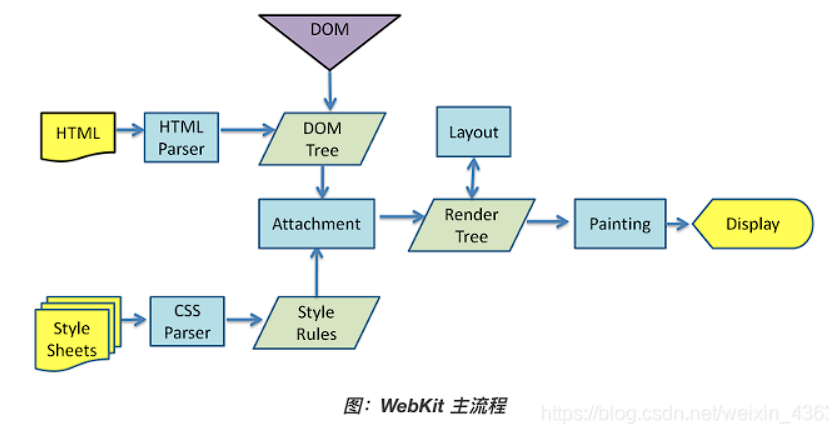
浏览器缓存策略
浏览器缓存的工作流程
首次请求:服务器返回资源及缓存策略(强缓存 / 协商缓存参数)
再次请求:
先检查强缓存是否有效,若有效则直接使用缓存(状态码200 (from cache))
若强缓存失效,发送协商缓存请求头(If-Modified-Since/If-None-Match)到服务器。
服务器验证后,若资源未更新,返回304,浏览器使用缓存;若更新,协商缓存失效,返回新资源
谁来定缓存策?最终控制权在服务器,浏览器完全听从服务器返回的缓存指令
强缓存和协商缓存
- 强缓存(本地缓存)
浏览器直接读取本地缓存,不与服务器交互,状态码为200关键响应头:
Expires:资源过期时间(绝对时间戳),若未过期则直接读取缓存
Cache-Control(优先级高于Expires):
max-age=秒数:资源在多少秒内有效,如max-age=3600表示 小时内缓存有效。
public:资源可被客户端和代理服务器缓存
private:资源仅可被客户端缓存
no-cache:并非不缓存,而是需要经过协商缓存验证
no-store:禁止任何形式的缓存,每次请求都从服务器获取
为什么我改了代码,页面没变?通常是因为静态资源(JS/CSS)命中了强缓存 - 协商缓存(服务器验证)
浏览器向服务器发送验证请求,验证资源是否更新,状态码为304,若未更新则使用缓存关键响应头:
第一次请求时服务器返回:
Last-Modified:资源最后修改时间。
ETag:资源的唯一标识(如文件哈希值)。
后续请求时浏览器发送:
If-Modified-Since:携带Last-Modified的值,询问服务器资源是否修改。
If-None-Match:携带ETag的值,询问服务器资源是否变更
服务器响应:
若资源未更新,返回304 Not Modified,浏览器使用本地缓存
若资源更新,返回200 OK及新资源内容
缓存策略的选择场景
强缓存适合:
静态资源(如图片、CSS、JS),版本稳定,更新频率低。
可设置max-age为较长时间(如 1 周),并通过 URL 版本号控制更新。
协商缓存适合:
动态数据(如用户信息页面),或更新频率较高但需缓存的资源。
避免强缓存导致数据过期,通过协商缓存确保数据时效性。
Cache-Control有哪些常用值
max-age=N:资源在 N 秒内有效,过期后需重新验证。
public:资源可被客户端和代理服务器缓存(如 CDN)。
private:资源仅客户端可缓存,代理服务器不可缓存(如用户登录信息)。
no-cache:强制浏览器发送协商请求到服务器,验证资源是否更新。
no-store:禁止任何缓存,每次请求都从服务器获取(如敏感数据)。
ETag相比Last-Modified有什么优势?
Last-Modified:资源最后修改时间。
ETag:资源的唯一标识(如文件哈希值
- Last-Modified有局限性:
只能精确到秒级,若资源在 1 秒内多次修改,无法识别
服务器时间同步问题可能导致判断不准 - ETag的优势:
基于文件内容生成哈希值,更精准判断资源是否变更
可解决Last-Modified的时间精度问题和服务器时间不一致问题
http和https
HTTP和HTTPS是两种用于在互联网上传输网页数据的协议。它们的主要区别在于安全性、连接方式、端口使用以及证书申请等方面
- 安全性
- HTTP 是一种明文传输协议,这意味着所有通过 HTTP 发送的数据都是未加密的,可以被任何能够访问网络流量的人轻易读取或修改。因此,HTTP 不适合用于传输敏感信息,如登录凭证、支付信息等 1。
- HTTPS 则是在 HTTP 基础上加入了 SSL/TLS 层,为浏览器和服务器之间的通信提供了加密。这确保了即使有人截获了通信内容,也无法直接读取或篡改这些信息。HTTPS 通过数字证书机制来验证服务器的身份,防止中间人攻击
- 连接方式
- HTTP 的连接非常简单且无状态,这意味着每次请求都是独立的,不会保存之前请求的状态信息
- HTTPS 需要先建立一个安全的 SSL/TLS 连接,然后才能进行加密的数据传输。这个过程包括客户端与服务器之间的一系列握手操作,以确定双方使用的加密算法并交换密钥
- 端口使用
- HTTP 默认使用的是80端口进行通信
- HTTPS 使用的是443端口,默认情况下,当您看到网址前缀是“https://”时,表示该网站支持HTTPS,并默认尝试通过443端口进行通信
- 证书申请
- HTTP 不需要任何证书即可工作。
- HTTPS 需要向证书颁发机构(CA)申请SSL证书。虽然存在一些免费证书选项,但通常情况下,获取受信任的证书需要一定的费用。
- 性能考虑
- 虽然 HTTPS 提供了更高的安全性,但这也意味着额外的计算资源消耗,尤其是在初始建立安全连接时的SSL/TLS握手过程中。然而,现代硬件和优化过的加密算法已经大大减少了这种性能开销
- SEO影响
- 搜索引擎更倾向于推荐使用 HTTPS 的网站,因为它们提供了更好的用户体验和更高的安全性。实际上,Google已经明确表示会给予 HTTPS 网站一定的排名优势
- 总结:
HTTPS 相较于 HTTP 提供了显著的安全增强,包括数据加密、身份验证和完整性保护,使得它成为处理敏感信息的标准选择。随着对网络安全重视程度的增加,越来越多的网站正在迁移到 HTTPS 协议。
GET和POST的区别
- 语义与设计目的:
- GET 是获取资源的请求,它是幂等的,多次执行不会改变服务器状态,比如加载页面、查询数据。
- POST 是提交数据的请求,它是非幂等的,多次提交可能产生不同结果,比如提交表单、创建订单。
- 参数传递方式:
- GET 的参数通过 URL 的查询字符串(Query String) 传递,比如
?name=John&age=20。参数可见,长度受浏览器 URL 限制(一般不超过 8KB)。 - POST 的参数通过 请求体(Request Body) 传递,支持更大数据量(如上传文件),且不会直接暴露在 URL 中。
- GET 的参数通过 URL 的查询字符串(Query String) 传递,比如
- 安全性:
- GET 的参数在 URL 中可见,可能被浏览器历史记录、服务器日志留存,不适合传递敏感信息(如密码)。
- POST 的参数在请求体中,安全性稍好,但如果未使用 HTTPS,两者都可能被中间人窃取。
- 浏览器行为差异:
- GET 请求可以被缓存和书签保存,比如重复访问同一 URL 时可能直接命中缓存;get请求可以通过点击后退或刷新按钮重复执行。
- POST 请求默认不缓存,且浏览器在刷新时可能会提示是否重新提交数据(防止重复操作)。
- 实际应用场景:
- 用 GET 的场景:搜索关键词、分页加载、获取静态资源(利用缓存优化性能)。
- 用 POST 的场景:用户登录注册(提交密码)、支付、下单(防止重复提交)、上传文件(大数据传输)。
- 补充细节:
- RESTful API 规范:GET 对应查询(Read),POST 对应新增(Create)。
- 幂等性:GET 的幂等性决定了它不应修改数据,否则可能导致缓存和爬虫的副作用。
- 编码格式:POST 支持更多格式(如 JSON),需通过
Content-Type指定,而 GET 只能是 URL 编码。
编码格式 - GET:参数默认使用 URL 编码(空格转
%20,中文转 UTF-8 等)。 - POST:支持多种编码格式,需通过
Content-Type指定
等性与副作用 - GET:幂等操作(多次执行结果相同,无副作用)。
- 设计 API 时应确保 GET 请求不修改服务器状态。
- POST:非幂等操作(每次提交可能产生新资源或修改数据)。
- 示例:多次提交同一表单可能生成多个订单
总结:
“简单来说,GET 和 POST 的核心区别在于语义和用途,而不是简单的‘谁更安全’。作为前端开发者,我会根据业务需求(如数据敏感性、幂等性要求)和浏览器特性(如缓存、URL 长度限制)选择合适的方法。
GET和POST的主要区别在于数据传递方式和用途:
- GET通过URL传参,适合查询数据,数据暴露在URL中,不安全
- POST 通过请求体传参,适合提交数据数据在请求体中,相对更安全
- GET请求是是幂等的(多次请求结果一致)
- POST非幂等(可能改变服务器状态)
- GET易被缓存,POST默认不缓存
- GET常用于查询数据(如搜索、分页)
- POST常用于提交数据(如表单、文件上传)
主流浏览器内核详解
浏览器内核的定义与作用
浏览器内核负责解析 HTML/CSS 并渲染页面,包含:
- 排版引擎:处理 HTML/CSS 布局(如盒模型计算)
- JavaScript 引擎:执行JS代码(如 V8)
- 网络栈:管理资源加载与缓存
四大主流内核对比
- Blink
特性:速度快,与Webkit兼容性好,支持最新的Web标准。
区别:在Webkit基础上进行了优化和改进,增加了对GPU加速渲染的支持,提升了性能和安全性。 - Gecko
特性:代码完全公开,可开发程度高,安全性强。
区别:独特的渲染方式和布局引擎,对网页标准的支持度高。 - Webkit
特性:渲染速度快,对HTML5和CSS3支持良好。
区别:早期苹果产品专用,后来开源并被多个浏览器采用。 - EdgeHTML
特性:专为Windows 10设计,与系统深度集成,提供流畅体验。
区别:已被Chromium内核取代,不再作为主流内核使用。
表格对比
| 内核名称 | 代表浏览器 | 特点 | 兼容性痛点 |
|---|---|---|---|
| Blink | Chrome、Edge、Opera | - Google 主导开发 - 更新迭代快(6周一个版本) - 高度支持最新 Web 标准 |
激进淘汰旧特性(如 Flash) |
| WebKit | Safari | - Apple 主导维护 - 移动端优化(iOS 强制使用) - 对电池续航有特殊优化 |
对 PWA 支持较晚 |
| Gecko | Firefox | - 开源社区驱动 - 严格遵循 W3C 标准 - 隐私保护功能强(如跟踪保护) |
市场份额低导致测试覆盖不足 |
| Trident | IE 11 及以下 | - 微软已停止维护 - 兼容模式(Quirks Mode)问题多 - 不支持现代 CSS/JS 特性 |
企业遗留系统仍需兼容 |
浏览器兼容性
浏览器兼容性问题
- 兼容性问题本质:
同一段前端代码在不同浏览器(或版本)中产生不同的渲染效果或功能异常 - 兼容性问题的根源和解决方案:
内核差异(渐进增强 + Polyfill)
版本迭代(强制升级 HTTPS)
厂商私有前缀(Autoprefixer 自动补全)
规范实现时序差(检测特性 + 降级方案 - 常见触发场景:
- HTML解析差异
不同浏览器对HTML标签的解析方式不同,可能导致页面结构异常。
解决方案:遵循HTML5标准,避免使用非标准标签和属性。 - CSS样式差异
不同浏览器对CSS属性的支持程度不同,可能导致布局、颜色、字体等样式不一致。
解决方案:使用CSS Reset或Normalize.css统一样式,添加浏览器前缀。 - JavaScript行为差异
浏览器对JavaScript语法和API的实现存在差异,可能导致代码在某些浏览器中报错或不生效。
解决方案:使用polyfill或特性检测,确保代码兼容性。 - 新特性支持差异
新版本的浏览器可能支持最新的Web标准和技术,而旧版本浏览器可能不支持。
解决方案:进行特性检测,提供降级方案或提示用户升级浏览器。
- 减少问题小结
- 选择浏览器:根据目标用户群体和项目需求选择合适的浏览器进行开发和测试。
- 处理兼容性:使用标准化的代码,借助工具和库处理兼容性问题,确保网站在不同浏览器上正常显示和运行。
浏览器兼容性测试的核心方法论
测试策略分层:
| 层级 | 测试内容 | 工具示例 |
|---|---|---|
| 基础渲染层 | HTML/CSS 解析、布局、字体渲染 | BrowserStack、LambdaTest |
| 交互功能层 | JavaScript 事件、表单验证、动态加载 | Selenium、Cypress |
| 视觉一致性层 | 像素级对比(跨浏览器样式一致性) | Percy、BackstopJS |
| 性能基准层 | 加载速度、内存占用、渲染帧率 | Lighthouse、WebPageTest |
企业级兼容性测试流程
静态代码分析
ESLint:检测潜在兼容性代码(如使用 fetch 未加 Polyfill)
Stylelint:检查 CSS 属性支持度(通过 stylelint-no-unsupported-browser-features 插件)动态测试阶段
首次渲染检查:通过无头浏览器(Headless Chrome)验证基础 DOM 结构
交互测试:使用 Cypress 录制用户操作路径(如搜索、表单提交)
视觉回归:通过 Percy 对比不同浏览器截图监控与反馈
生产环境监控:集成 Sentry 捕获浏览器端错误(按 UA 分类)
用户反馈闭环:如在 Hugo 站点添加「报告问题」按钮,收集用户环境信息
https详细理解
HTTPS 是怎么保证安全的?为什么比 HTTP 安全
HTTPS 通过 SSL/TLS 实现加密通信和身份验证。
具体流程包括:1. 客户端与服务器协商加密算法;2. 服务器发送证书;3. 客户端验证证书并生成会话密钥;4. 双方使用会话密钥加密数据
加密通信:通过 SSL/TLS 协议对数据进行加密。
身份验证:服务器证书验证身份,防止中间人攻击。
数据完整性:使用消息摘要(如 SHA-256)确保数据未被篡改
作为前端,你无需配置服务器证书,但必须确保所有资源加载、API 请求使用 HTTPS,处理混合内容问题,并理解其背后的安全逻辑
“HTTPS 是通过 加密传输、身份认证 和 数据完整性校验 三个核心机制来保证安全的,它解决了 HTTP 的明文传输、数据篡改和身份伪造三大风险。具体来说:
- 加密传输(防窃听)
- HTTP 的问题:数据以明文传输,容易被中间人窃听(如密码、Cookie)。
- HTTPS 的解决方案:
- 混合加密机制(TLS 握手):
- 非对称加密:客户端用服务器的公钥加密一个随机数(Pre-Master Secret),传给服务器(只有服务器私钥能解密)。
- 对称加密:双方基于随机数生成会话密钥,后续通信使用对称加密(如 AES),兼顾安全性和性能。
- 效果:即使数据被截获,攻击者无法解密内容。
- 混合加密机制(TLS 握手):
- 身份认证(防伪装)
- HTTP 的问题:无法验证服务器身份,容易遭受中间人攻击(如假冒银行网站)。
- HTTPS 的解决方案:
- 数字证书:服务器向权威机构(CA)申请证书,证书包含公钥、域名、有效期等信息,并由 CA 用私钥签名。
- 验证流程:
- 客户端内置信任的 CA 公钥,收到证书后验证签名是否合法。
- 检查证书域名是否匹配、是否过期。
- 效果:确保客户端连接的是真实服务器,而非中间人。
- 数据完整性校验(防篡改)
- HTTP 的问题:数据在传输中可能被篡改(如插入广告代码)。
- HTTPS 的解决方案:
- 散列算法 + 数字签名:
- 发送方对数据计算哈希值(如 SHA-256),用会话密钥加密哈希值(即 HMAC)。
- 接收方解密后重新计算哈希值,与传来的哈希值比对。
- 效果:若数据被篡改,哈希值不匹配,连接会被终止。
- 散列算法 + 数字签名:
由于我没有使用过https,追问了deepseek老师:
作为前端开发者,使用 HTTPS 需要关注以下核心事项
- 资源引用:确保所有资源使用 HTTPS**
- 静态资源(图片、字体、脚本、样式)
- 绝对路径:直接使用 HTTPS URL:
- 相对协议(自动匹配页面协议):
- 避免硬编码 HTTP:
- 第三方库和 CDN
- 检查第三方服务是否支持 HTTPS(如 Google Fonts、Bootstrap CDN 默认支持)。
- 若第三方不支持 HTTPS,需更换服务商或自托管资源。
二、API 请求:强制使用 HTTPS 协议
- 前后端通信
- 生产环境 API 地址必须为 HTTPS
- WebSocket 连接
- 使用
wss://替代ws://:三、开发环境:本地启用 HTTPS1
const socket = new WebSocket('wss://realtime.your-service.com');
- 使用
- 为什么要用 HTTPS 开发?
- 模拟生产环境行为(如 Service Worker、地理定位 API 仅限 HTTPS)。
- 测试混合内容问题。
- 启用方法
- 使用前端工具链自动配置:
# Create React App HTTPS=true npm start # Vite vite --https - 手动生成证书(适合自定义场景):
- 安装
mkcert:生成本地可信证书。 - 生成证书:
mkcert localhost 127.0.0.1 ::1 - 在
vite.config.js或webpack.config.js中配置证书路径。
- 安装
- 使用前端工具链自动配置:
四、处理混合内容(Mixed Content)
- 什么是混合内容?
- HTTPS 页面中加载了 HTTP 资源(如图片、脚本、样式)。
- 浏览器会阻止加载这些资源(控制台显示警告)。
- 解决方案
- 代码检查:全局搜索代码中的
http://,替换为https://或//。 - 内容安全策略(CSP):强制所有资源使用 HTTPS
,关于 HTTP 状态码,我会从分类、常见状态码的意义以及 HTTPS 的关系三个方面来回答:
- 代码检查:全局搜索代码中的






