正则表达式篇
学习资料
B站正则表达式视频课
B站up胶囊大人的视频(这个讲得好)
练习网站regex101
正则练习:(https://codekjiaonang.com/)
编程胶囊(图片里的练习例子来源于这里)
不太好理解的笔记github
这边笔记总结了多个视频课教程的知识点,元字符笔记有点冗杂,但是总体详细清晰,难理解部分的有理解文字+举例讲解
基本概念
正则表达式(Regular Expression, 简称 regex 或 regexp)是一种用来匹配字符串的模式
它可以用于搜索、编辑或操作文本和数据
正则表达式就像一个小弟,永远要跟着一个大哥,所以正则表达式一定要跟着一个数组
正则表达式用来做对字符串的增删改查
绝大部分场景都能用正则表达式
比如下图,想要提取出字符串里的数字用正则表达式明显更简单快捷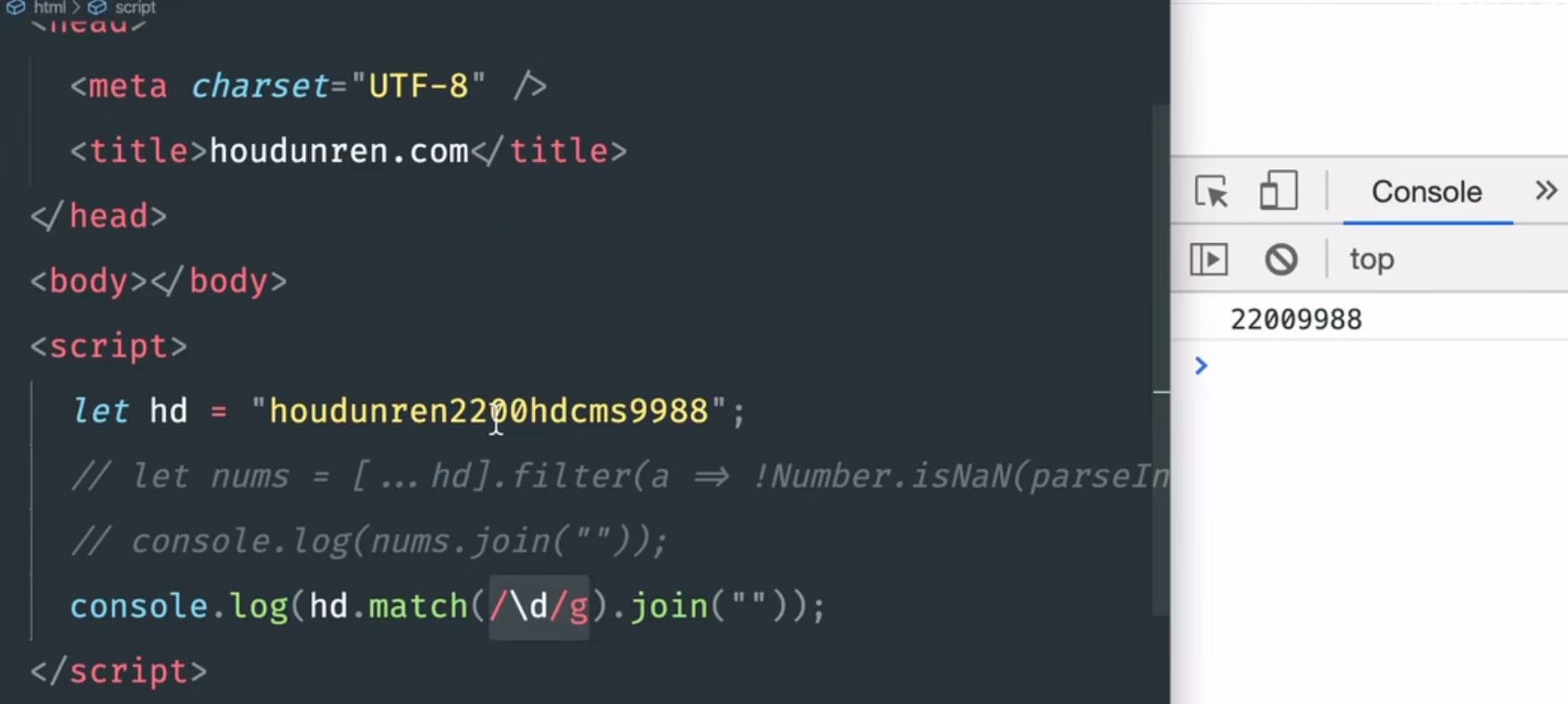
创建正则表达式
用两个斜线包裹字面量/字面量/
注意这种方法不能操作变量,大部分时候也不会放
元字符
字符组用[中括号包裹]
字符组:匹配中括号里面出现的元素任意一次,如匹配java或Java:[jJ]ava
**在字符组中可以用短横线-**来匹配0-9所有数字,所有小写字母a-z,所有大写字母A-Z,合起来匹配所有的数字和大小写字母/[0-9a-zA-Z]/
用转义符来匹配特殊字符:
如想要匹配特殊符号-,那么要先对它使用\进行转义,即\-就代表了-符号本分
快捷方式--大写取反
\b 匹配单词边界,如\bname\b这样匹配到完整的name这个单词
\d 数字字符(等价于[0-9])
\D 非数字字符 (等价于^[0-9])
\w 单词字符(字母、数字、下划线)
\W 非单词字符 (特殊字符如+-可以匹配)
\s 空白字符(空格、制表符TAB,换行符)
\S 非空白字符 (非空白字符). 任意字符,匹配非换行符\n的任意字符,它只能出现在方括号以外,
如:匹配任意字后面是vo的字符串/.vo/? 可选字符,放在字符后面,匹配可以出现也可以不出现的
如:/colou?r/匹配color和colour
其他字符
? 前面的字符出现1或0次(0或1次)* 匹配>=0个重复的在*号之前的字符(0或多次)+ 匹配>=1个重复的+号前的字符 (1或多次){n,m} 匹配n–m个个大括号之前的字符或字符集 (n <= 次 <= m) 第二个参数m可省
(xyz) 字符集,匹配与 xyz 完全相等的字符串. 匹配任意单个字符,除了换行符[ ] 字符种类。匹配方括号内的任意一个字符[^ ] 否定的字符种类。匹配除了方括号里的任意字符| 或运算符,匹配符号前或后的字符\ 转义字符,用于匹配一些保留的字符 [ ] ( ) { } . * + ? ^ $ \ |
^ 从行首开始匹配 ^a匹配行首的a$ 从末端开始匹配 a$匹配行尾的a
.* 匹配所有的字符[a-z]匹配所有小写字母[A-Z]匹配所有大写字母[0-9]匹配所有数字[a-zA-Z0-9]匹配所有英文字符和数字
^配合[]使用才代表非[^c]ar匹配一个后面跟着ar的除了c的任意字符[^a-z]匹配所有非小写字母[^A-Z]匹配所有匹配所有非大写字母[^0-9]匹配所有匹配所有非数字字符,匹配到的包括换行符[^a-zA-Z0-9]匹配所有匹配所有非英文字符和数字
开始和结束
^代表开头,$代表结尾
(^放在区间里面代表取反,放在区间外面代表开头)
($放在结尾的单词后面)
如要匹配以ovo结尾的部分/ovo$/
多次匹配 {大括号包裹}
{固定次数}比如要匹配九个数字/\d{9}/{区间次数},比如要匹配2或3个数字/\d{8,9}/ {区间次数}?,?表示非贪婪模式,找到了那么久不往后再找了,比如匹配到八个数字的那么就不匹配九个数字了/\d{8,9}?//{0,}/,匹配0到无数多的区间,等价于+加号{1,}/,匹配1到无数多的区间,等价于*星号
分组(小括号包裹)(重点)
分组用来提取数据
如图例子用分组提取学号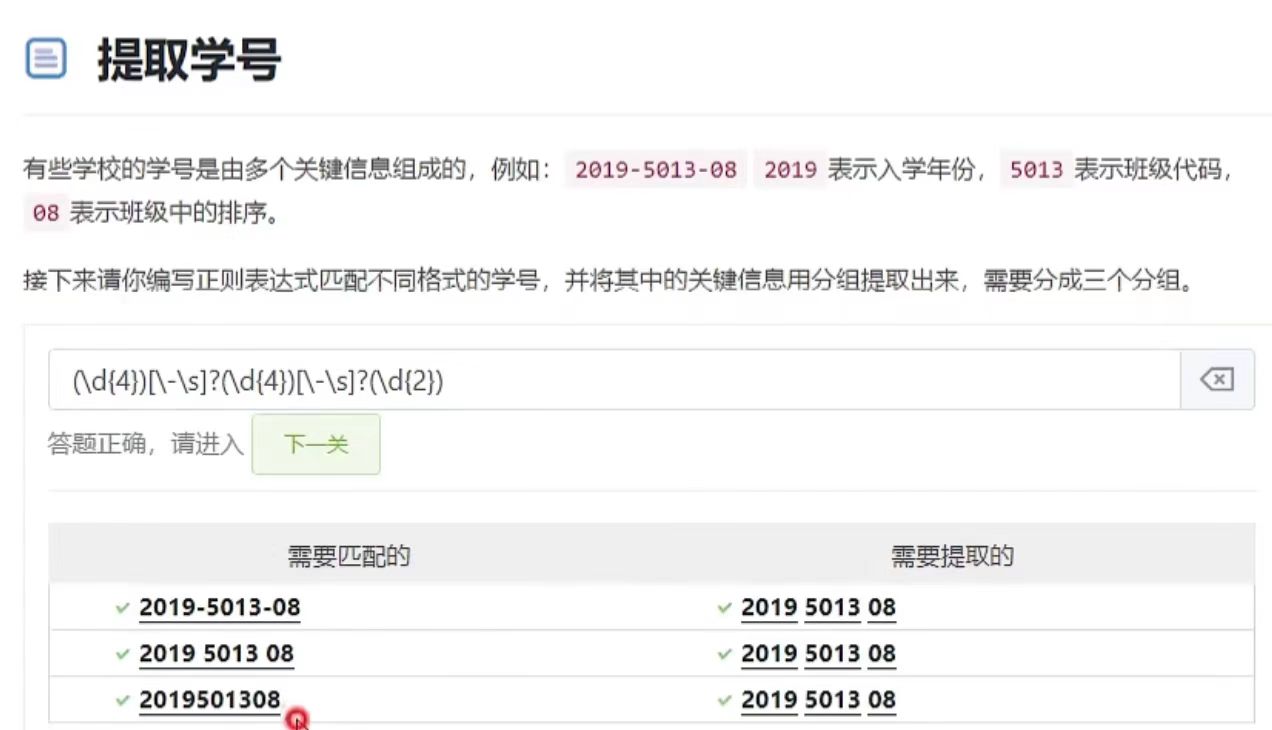
分组中或者条件 | 竖线
非捕获分组(?:表达式)
用于不需要捕获某个分组的内容,但是又想使用分组的特性
如例子从数据中提取电话号:
分组的回溯引用 \分组数字
常用在标签中,提取指定标签中包裹的内容/<(\w+)>(.*?)</\1>/ 注意这里的/是结束标签需要的/,这里的回溯引用是\1,代表的是第一个分组中的内容
比如下图例子,匹配abba这种样式的单词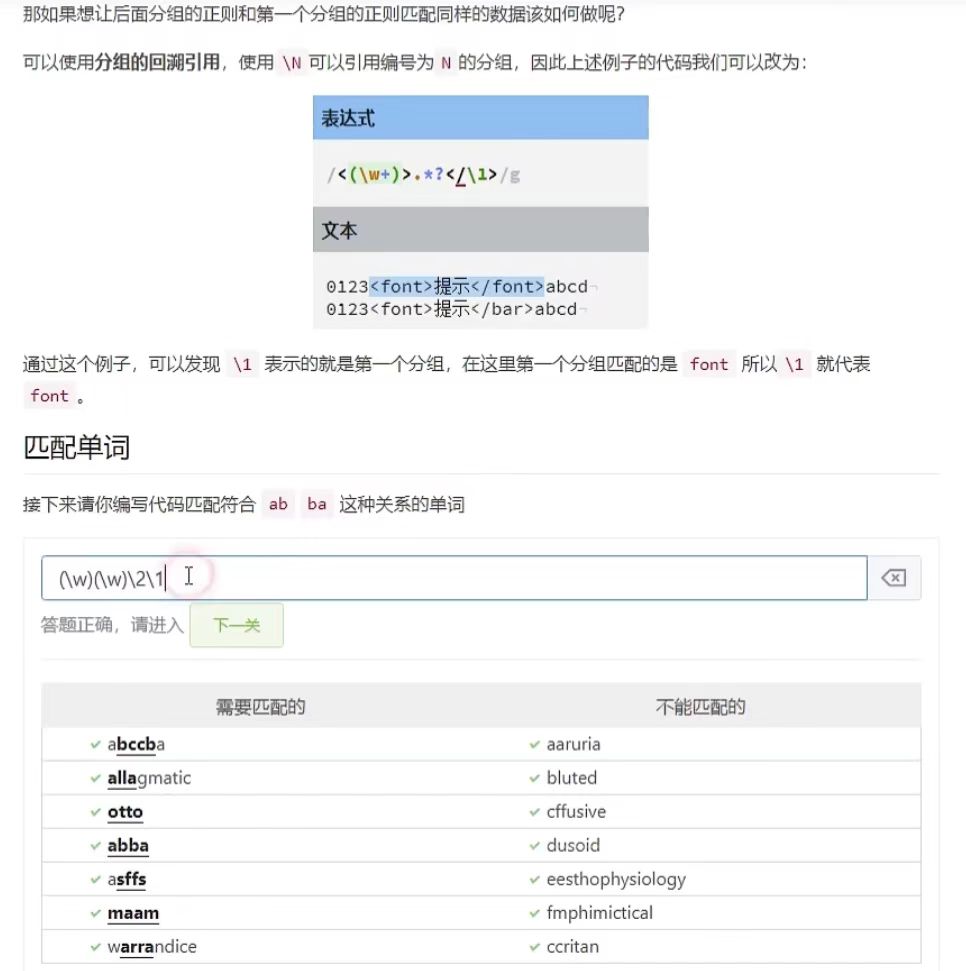
捕获组编号规则
$1 第一个捕获组的内容 (\d)→$1 → 原样保留数字
$& 整个匹配的内容 a→$& → 保持 a 不变$ 插入美元符号本身 需转义为 $$
按左括号(的出现顺序编号:(A)(B(C)) → $1=A, $2=B, $3=C
断言
断言一共有四种,正向反向先行后行断言
先行和后行断言的区别:先行断言从左往右看,后行断言从右往左看
我觉得,先行就是要匹配小括号表达式前面的内容,后行就是要匹配小括号右边的内容(这样适合我记忆,文档里描述的我记起来晕)
正向和反向断言的区别:正向断言要能匹配到括号里面的,反向断言要不能匹配到括号里面的
正向要表达式里的,反向不要表达式里的
先行断言-正向先行断言
(?=表达式),表示在某个位置向右看,所在位置的右侧必须能匹配表达式,先行断言可以用来判断字符串是否符合特定的规则
比如:想要提取出泽兰这两个字同时要求泽兰两个字后面是雾刃,那么要写成/泽兰(?=雾刃)/
再比如,下图,提取包含至少一个大小写字母的字符串: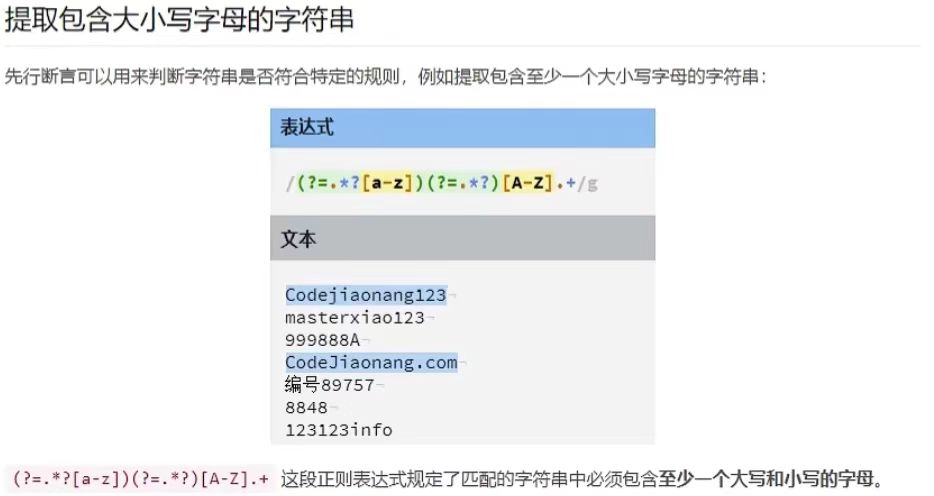
又比如下图,验证密码强度例子,但是这里的最后应该是{8,}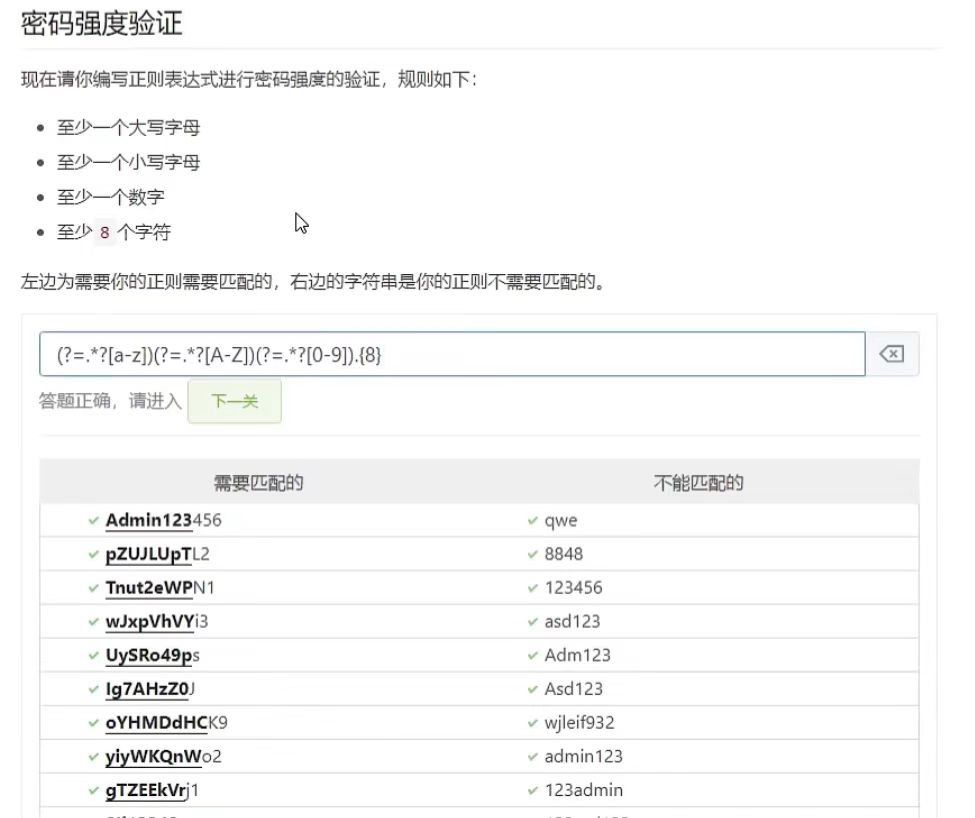
先行断言-反向先行断言
(?!表达式),表示在某个位置向右看,所在位置的右侧不能匹配某字符
比如:想要提取出泽兰这两个字同时要求泽兰两个字后面不能是寻歌,那么要写成/泽兰(?!寻歌)/
再比如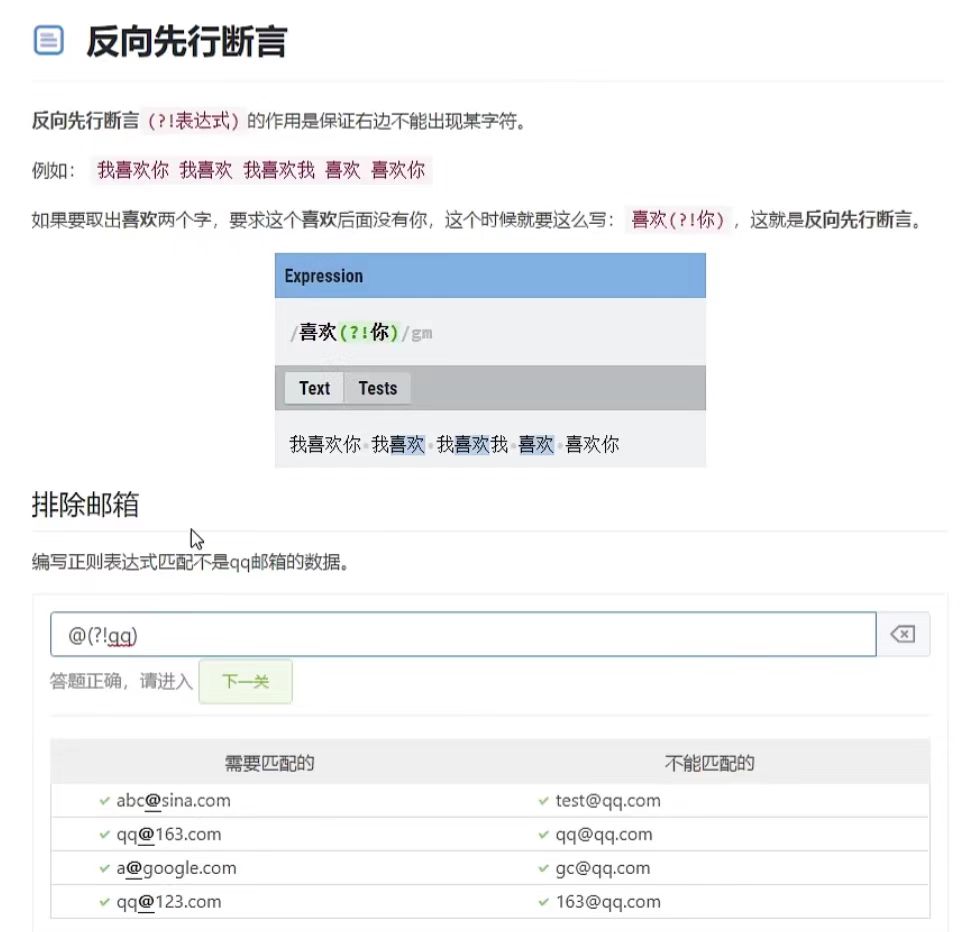
后行断言-正向后行断言
(?<=表达式),表示在某个位置向左看,所在位置的左侧必须能匹配表达式
例子看图片吧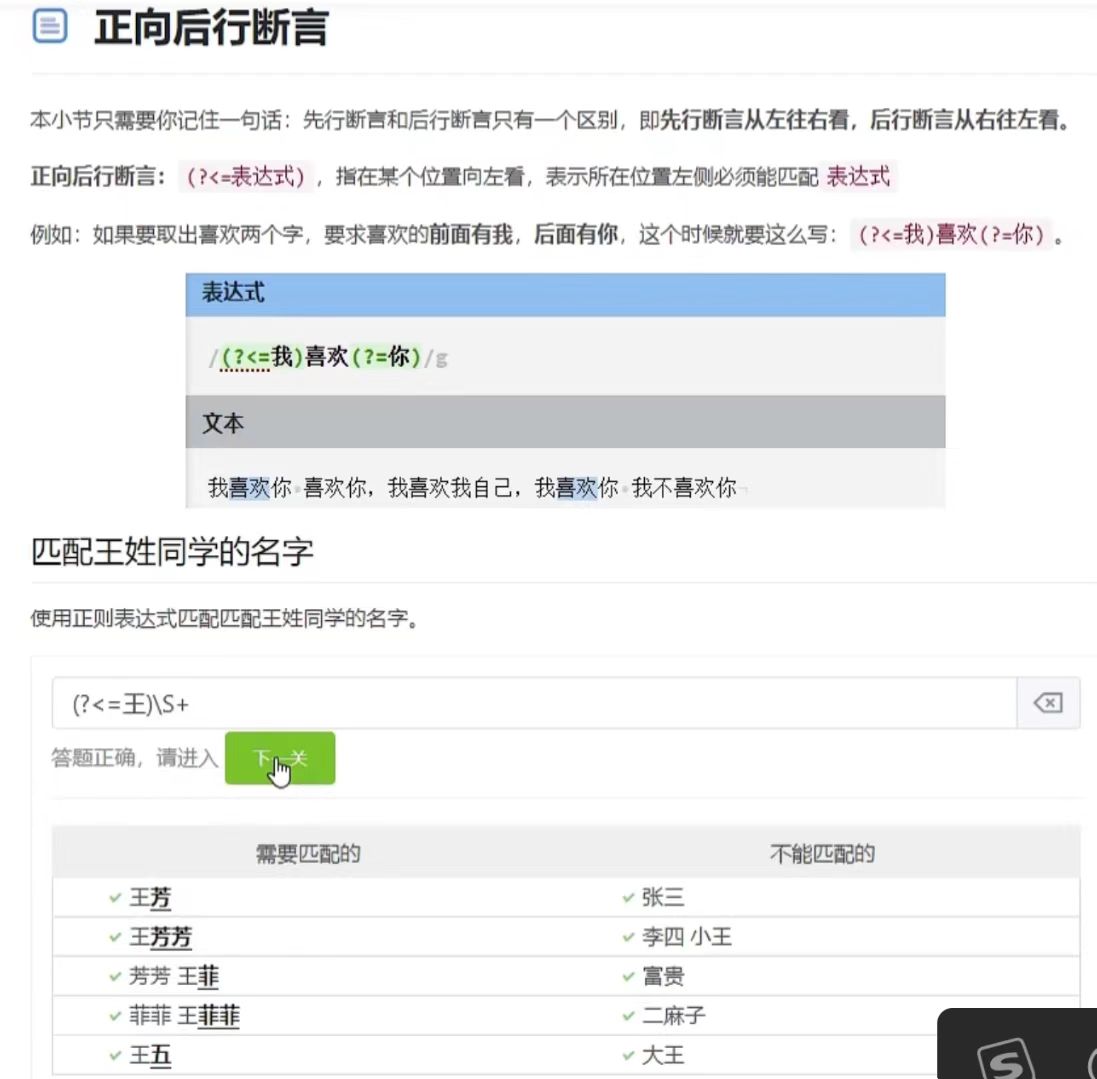
后行断言-反向后行断言
(?<=表达式),表示在某个位置向左看,所在位置的左侧必须不能匹配表达式
看图片例子理解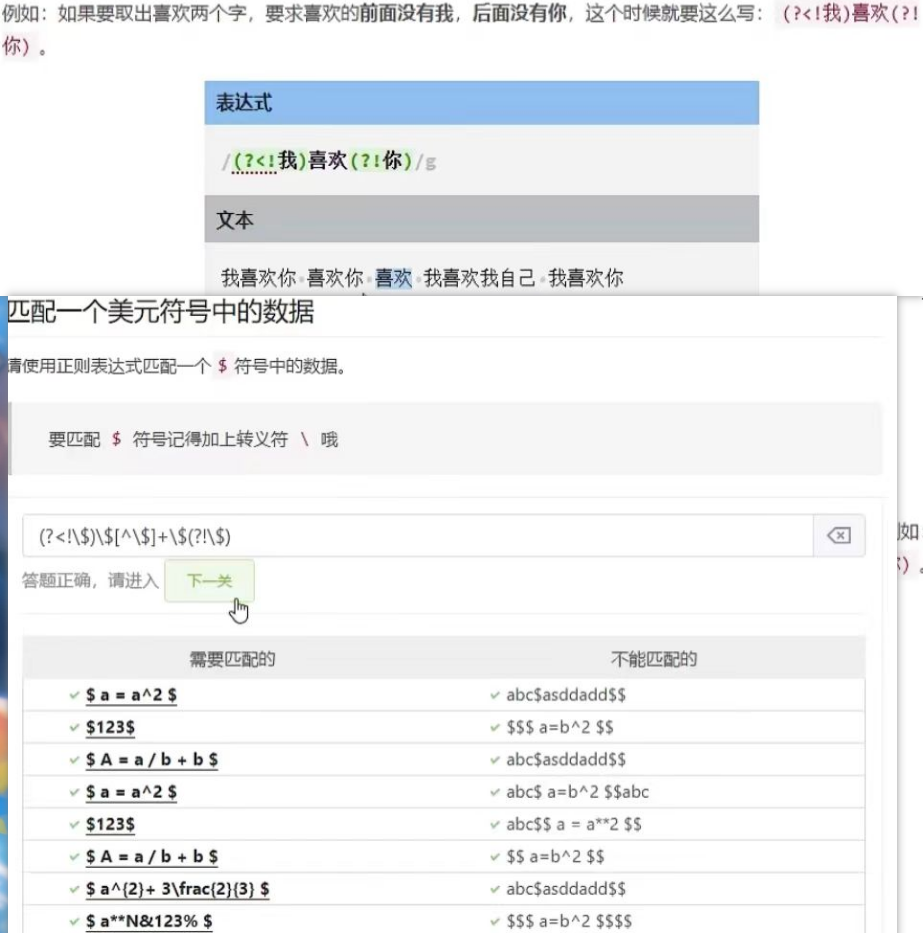
常用方法
slice方法
数组和字符串中都有slice方法
slice(m,n) 按照下标截取,包括m,不包括n
string.slice(0, 3) 索引从0开始不包括3
全局搜索/g
当使用 /g 标志时,正则表达式会查找字符串中所有匹配的子串,而不仅仅是第一个找到的匹配项
影响匹配方法的行为
在不使用 /g 标志的情况下,.match()、.exec() 等方法只会返回第一个匹配的结果(如果有的话)
使用 /g 标志时,这些方法可以找到并返回所有匹配项(例如,.match() 返回一个包含所有匹配项的数组)
对于 .replace() 方法,没有 /g 标志时,只会替换第一个匹配项;带有 /g 标志,则会替换所有匹配项
例子
- 不带 /g 的例子
1
2
3const str = "Hello World!";
const regex = /[aeiou]/; // 查找元音字母
console.log(str.match(regex)); // 输出 ["e"] - 带 /g 的例子
1
带 /g 的例子
什么时候使用
- 需要找到所有匹配项:
如果你的应用场景要求找到字符串中的所有匹配项,而不是仅第一个,那么你应该使用 /g 标志。比如统计文本中某个单词出现的次数,或者替换掉文本中所有匹配的子串。 - 循环匹配:
在某些情况下,你可能希望在一个循环中反复调用 .exec() 或者 .test() 来遍历所有匹配项。在这种情况下,使用 /g 标志是必要的。 - 替换操作:
当你想要替换字符串中所有匹配的子串而不是仅仅替换第一个匹配项时,应该使用 /g。例如,将文本中的所有空格替换为下划线:1
2const text = "This is a test.";
console.log(text.replace(/ /g, "_")); // 输出 "This_is_a_test."
例子
- 格式化电话号码
1
2"13812345678".replace(/(\d{3})(\d{4})(\d{4})/, "$1-$2-$3");
// 输出:138-1234-5678 - 日期格式转换
1
2"20230815".replace(/(\d{4})(\d{2})(\d{2})/, "$1/$2/$3");
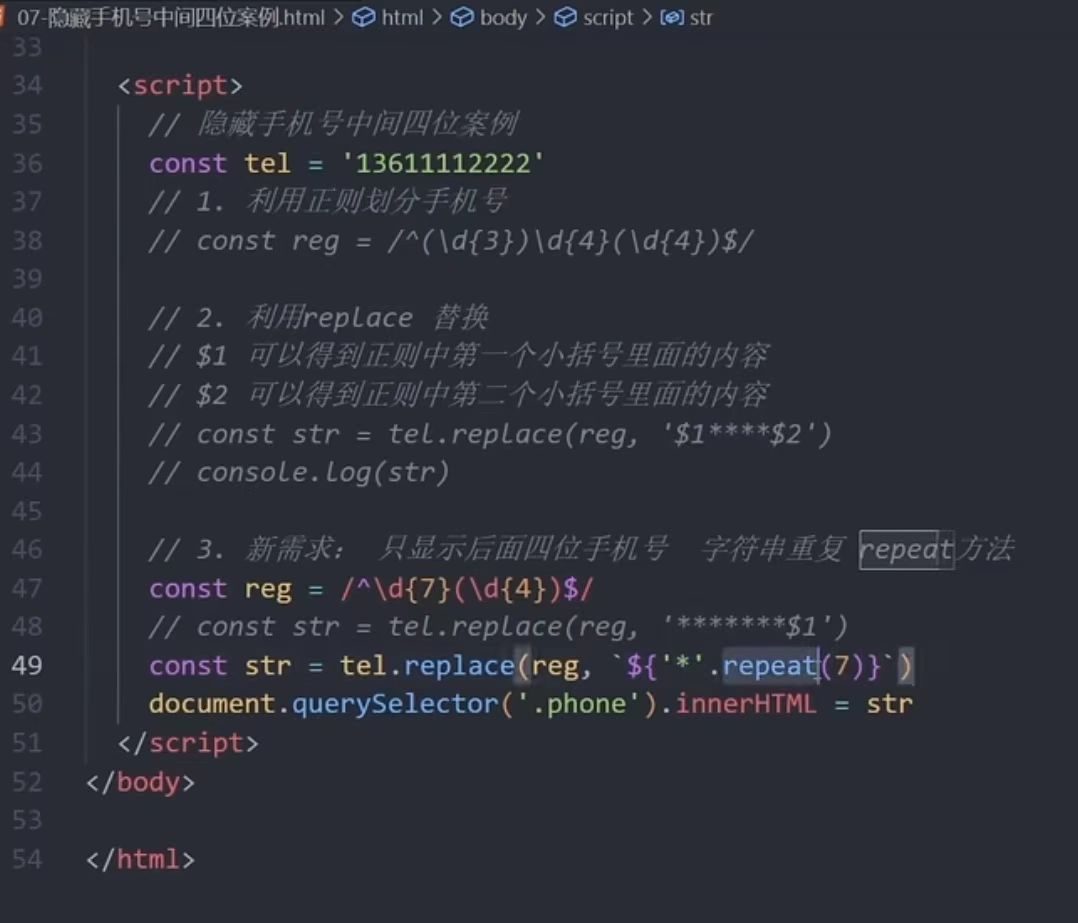
// 输出:2023/08/15 - 隐藏手机号中间四位
1
2"13812345678".replace(/(\d{3})\d{4}/, "$1****");
// 输出:138****5678 - 表单验证
1
2
3
4
5
6
7
8
9
10
11// 电子邮箱
/^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$/
// 手机号码(中国大陆)
/^(?:(?:\+|00)86)?1[3-9]\d{9}$/
// 身份证号码(18位)
/^[1-9]\d{5}(?:18|19|20)\d{2}(?:0[1-9]|1[0-2])(?:0[1-9]|[12]\d|3[01])\d{3}[\dX]$/
// 密码强度(至少8位,含大小写字母和数字)
/^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)[\w!@#$%^&*]{8,}$/1
用正则表达式隐藏手机号中间四位1